
大数据计算方法系统具有国际影响力
研发家
|
2025-05-01
20
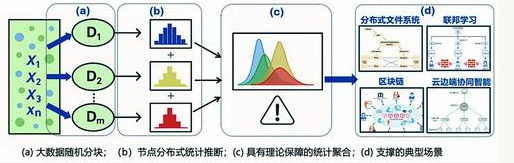
在国家自然科学基金重大研究计划“大数据驱动的管理与决策”的支持下,研究团队克服了分布式计算、极高维建模、缺失态推断等关键科学问题,建立了具有国际影响力的大数据计算理论和方法体系。针对数据规模庞大、模式复杂、价值稀疏等管理情况下的长期挑战。传统集中计算方法存在计算效率低、隐私暴露风险高等突出问题,分布式计算方法常用于应对这种情况。如何高效整合这些“碎片化”的准确性和准确性?
过去,分布式计算通常采用“算术平均”或“最佳代表”进行信息聚合,其合理性和优势得不到有效保证。因此,研究小组提出了基于加权平均法的分布式统计,理论上证明了分布式统计的良好数学特性和计算性能。
此外,研究小组还考虑了现实场景中数据异质性的出现,构建了基于最佳加权策略的分布式统计及其有效性理论。这一系列研究不仅为分布式计算和联合机器学习提供了关键的理论指导,也为构建高效、安全、可扩展的数据智能系统奠定了基础。
在战略决策情况下,大数据往往具有高度稀疏的特点,存在数据缺失和不确定性等问题,从而给理论建模和科学决策的准确性带来严峻的考验。
例如,研究团队从战略决策情况出发,指出数据的缺失与用户特征、产品属性等诸多因素密切相关,应该是“非随机缺失”,而不是之前假设的“随机缺失”。基于此,研究团队创新性地提出了矩阵填充系列方法,在非随机缺失的情况下进行非随机填充。这是一种完全由数据驱动的填充方法,无需假设缺失系统。这种“无模型”的新方法不依赖任何先验信息,即使缺失机制完全未知,也能高效准确地填补缺失值。
上述研究成果构建了具有国际影响力的理论和方法体系。同时,研究团队在重点行业和典型企业中进行了成果实践验证和应用示范,充分展示了基础研究对重大行业场景的推动作用。
赞一个
11
版权及免责声明:本网站所有文章除标明原创外,均来自网络。登载本文的目的为传播行业信息,内容仅供参考,如有侵权请联系删除。文章版权归原作者及原出处所有。本网拥有对此声明的最终解释权
更多服务












最新文章
NEW
热点资讯
HOT
学术资源免费领取
加微信领取20G科研大礼包!
更有众多热门
更有众多热门




RDLINK研发家 版权所有 Copyright©2023 All rights reserved

