
新的人工智能模型准确估计了中国南方单季和双季水稻的增产潜力
明确作物实际产量与潜在产量之间的产量差距,对提高农业生产力、保障国家粮食安全具有重要意义。然而,中国南方的单季和双季水稻种植方法是混合的。在单季和双季水稻混合种植的农业系统(以下简称“混合系统”)中,传统方法难以有效识别不同类型水稻的产量组成,导致对水稻产量增加潜力评价存在较高的不确定性。
近日,中国科学院深圳先进技术研究院数字研究所研究员陈金松、助理研究员王靖文在《农业计算机与电子》工业期刊上发表了最新研究。该团队提出了一种以知识为导向的机器学习(KIML)建模框架突破了当前混合系统中单季稻和双季稻产量标签缺乏对传统人工智能建模的限制,完成了对南方单季稻和双季稻混合区产量构成的准确识别和定量评价。在本研究中,助理研究员王静文是论文的第一作者,陈金松是论文的共同通讯作者。深圳先进研究院是该研究的第一个单位。
目前,混合系统中可用的产量样本数据一般只包括种植区单季稻和双季稻的混合平均值,难以支持人工智能模型学习,识别不同稻作类型的产量组成。针对这一问题,研究人员引入遥感技术提取的作物种植强度数据,将其转化为结构性知识约束,嵌入人工智能模型培训过程中,引导人工智能模型在学习过程中自动实现混合产量组成的合理解耦,实现混合系统中多种水稻产量的定量识别。
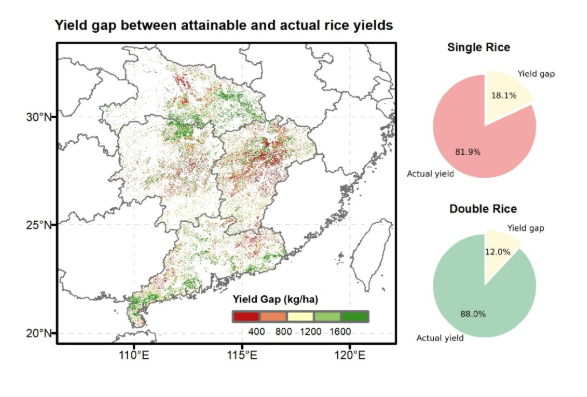
验证结果显示,KIML模型对南方混合区单季稻和双季稻产量的估算精度分别达到85.8%和89.8%,有效纠正了传统机器学习模型低估单季稻产量与双季稻产量的高估误差,显著提高了后续增产潜力评价的稳定性,估算精度提高了12.1%左右。数据显示,在目前的种植模式下,南方混合区(湖南、湖北、江西、广东)水稻的实际产量水平与潜在产量之间仍有约1235万吨(13.9%)的增产空间,其中单季稻和双季稻分别贡献46.2%和53.8%。
由于传统的机器学习方法难以准确识别单季和双季水稻产量的组成,对水稻整体增产潜力的估算具有重要意义。“提高混合区水稻增产潜力的估算精度,对牢牢把握粮食安全形势具有重要意义。我们利用KIML模型学习分析单季和双季水稻混合平均产量信息,完成对单季和双季水稻增产潜力的准确估算,有望为我国南方粮食主产区科学制定种植策略、优化资源配置、提高粮食生产提供坚实的数据支持。”论文通讯作者陈劲松表示,本研究是先验知识与智能学习相结合的重要进展,增强了人工智能模型对复杂系统的推理和解释能力,有效促进了人工智能在农业领域的深度应用。
赞一个












更有众多热门





