
数据库文章要黄?已被多本国际期刊抵制!
据Science 报道,Scientific Reports 副主编Matt Spick发现大量利用美国国家健康与营养调查(NHANES)数据的公式化论文大量涌入Scientific Reports、PLOS Biology等期刊中。这些低质论文的激增,可能是由“论文工厂”主导,并通过AI生成文本提供便利。
Nature 也在近期的报道中指出,除了NHANES,其他生物医学数据库(UK Biobank、FAERS、GBD和FinnGen)也频繁被这些低质论文利用。
面对这一问题,Journal of Global Health 已经率先采取行动,收紧了对基于这些数据库的论文的审核标准。现在,使用开放数据集投稿的作者必须声明过去三年内使用类似数据集发表过多少篇论文,披露是否使用人工智能撰写手稿,并解释其如何排除结果中的假阳性。
为应对“滥用数据集”的趋势,其他期刊和出版商或将效仿Journal of Global Health,引入类似的严格审核机制。
根据Matt Spick、Anthony Onoja等人的研究,2021年-2025年间,有六个数据集的论文数量远超预期增长,其中NHANES、UK Biobank、FAERS、GBD和FinnGen这五个数据源的“模板化”论文爆发式增长。
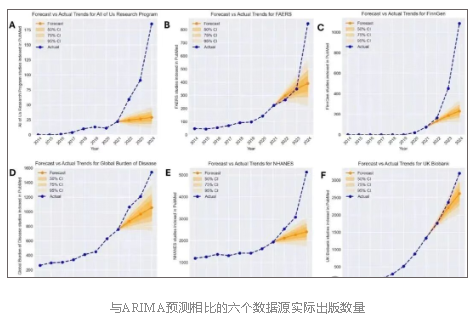
这些低质论文往往选取某种健康问题、关联的环境或生理因素,以及特定人群的已公开数据,通过简单替换变量生成所谓的“新发现”,如饮用半脱脂牛奶与预防抑郁症(PMID 39703337)或受教育程度与术后腹疝(PMID 39616067)之间,以及许多其他缺乏生物学基础的假设。“模板化”
在检查这六个数据源论文的地理来源变化时,研究发现来自中国的论文从2021年占PubMed数据库索引论文的19%猛增至2024年的65%,为所有国家/地区中增长最多的。在这六个数据集中,FinnGen数据源的中国论文增长最为显著,截至2024年,89%相关论文的主要作者来自中国。
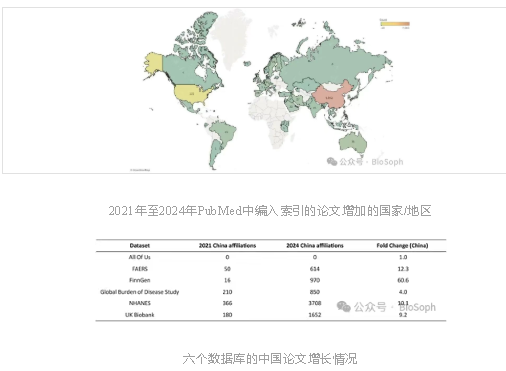
这种论文产出的不平衡分布表明,这种增长并非研究生产力的普遍提高,而是发展中国家的研究人员在“不发表就灭亡”的学术压力下,因缺乏科研支持而铤而走险,最终助长了”论文工厂“的发展。
《Expert Opinion on Drug Safety》和《Frontiers in Pharmacology》为应对大量同类稿件的冲击,前者于7月底宣布全面停止接收使用FAERS数据库的投稿;后者开始要求基于公共数据库的研究必须提供独立验证。
赞一个
- 文章标签:
- 高校动态












更有众多热门





